El volumen de acciones de tutela en Colombia es una presión concreta que llega a los despachos judiciales en forma de pilas de papel, carpetas escaneadas y correos que acumulan términos. En un juzgado donde trabajé, las tutelas llegaban sin parar los lunes, miércoles y viernes, sin importar qué otro proceso estuviera en curso. El plazo de diez días para fallar no negocia. Cuando vi lo que Alexander Oviedo Fadul publicó en Ollama, lo primero que pensé fue que eso necesitaba existir hace años.
Qué es TutelaBot y quién lo construyó
TutelaBot es un modelo de lenguaje construido por Alexander Oviedo Fadul (bladealex en GitHub y Ollama), especializado en el análisis de acciones de tutela colombianas. Corre sobre Llama 3.2, pesa 2.0 GB, tiene una ventana de contexto de 128.000 tokens y produce salidas en JSON estructurado. Es software libre, corre localmente con Ollama, y se instala en un comando:
ollama run bladealex/tutelabot
Alexander lleva tiempo construyendo herramientas para el ecosistema legal colombiano desde adentro del problema, con el conocimiento de quien lo vive a diario. TutelaBot es la expresión más concreta de eso que he visto.
Por qué la tutela es el caso de uso perfecto
La acción de tutela, consagrada en el artículo 86 de la Constitución Política y reglamentada por el Decreto 2591 de 1991, es el mecanismo de protección de derechos fundamentales más usado en Colombia. Se interpone ante cualquier juez, tiene un término de fallo de diez días establecido en el artículo 29 de ese Decreto, y cada año se tramitan millones en el país. Lo que la hace ideal para un modelo de IA es su estructura interna. Una tutela bien presentada tiene partes procesales identificables, hechos ordenados cronológicamente, derechos invocados citados expresamente, pretensiones claras y pruebas allegadas. Esa repetición estructural es exactamente lo que un modelo de lenguaje puede procesar de forma consistente y sin fatiga.
El problema real está en leer la décima tutela de la semana con el mismo nivel de atención que la primera, verificar los mismos requisitos procesales, extraer los mismos campos, y hacerlo dentro de un plazo que no cede. Es trabajo cognitivamente intenso y cronológicamente comprimido. Un modelo especializado en ese patrón es una herramienta de trabajo concreta.
Cómo funciona en la práctica
Después de instalar Ollama y correr ollama run bladealex/tutelabot, el flujo es directo. Pegas el texto de la tutela y el modelo extrae la información en formato JSON con los siguientes campos:
{
"tipo_documento": "Acción de tutela",
"fecha": "...",
"radicado": "...",
"despacho": "...",
"accionante": "...",
"accionado": "...",
"terceros": [...],
"hechos": [...],
"derechos_invocados": [...],
"pretensiones": [...],
"pruebas": [...],
"decisiones": [...]
}
El output JSON estructurado importa. Cuando el resultado es predecible y parseable, puede alimentar directamente un sistema de gestión, una base de datos o un script de automatización. Para quien está construyendo pipelines de automatización judicial, eso cambia completamente lo que es posible hacer con el análisis.
Los requisitos procesales que revisa
TutelaBot también verifica los requisitos procedimentales que cualquier despacho debe revisar antes de entrar al fondo del asunto. Los tres son exactamente los que importan.
Legitimación. Quién tiene derecho a presentar la acción, en nombre de quién y contra quién puede dirigirse. En tutelas mal formuladas, este es el primer punto de quiebre.
Subsidiariedad. La tutela procede cuando no existe otro mecanismo de defensa judicial idóneo. Si el accionante tiene a disposición otro recurso efectivo, la tutela puede ser improcedente, y verificarlo requiere leer los hechos con suficiente cuidado para entender qué vías ya intentó.
Inmediatez. La tutela debe interponerse en un tiempo razonable desde que ocurrió la vulneración del derecho. No hay plazo explícito en la norma, pero la jurisprudencia lo exige. Identificar si hay un problema de inmediatez implica cruzar la fecha de los hechos con la fecha de presentación.
Que el modelo revise estos tres requisitos no le ahorra al despacho el análisis. Lo que hace es permitirle llegar a ese análisis con una primera lectura ya hecha, con los campos relevantes identificados y organizados.
Lo que TutelaBot no hace, y por qué eso también importa
TutelaBot es una herramienta de apoyo. No decide, no falla, no reemplaza al juez ni al abogado. Eso viene de la naturaleza del problema, porque las tutelas involucran vidas reales, derechos fundamentales, plazos que tienen consecuencias jurídicas concretas. El criterio que se necesita para resolver una tutela se construye con formación jurídica, con lectura de jurisprudencia, con la responsabilidad de firmar una decisión. Eso no lo entrena un modelo en 2 GB.
Lo que el modelo sí puede hacer es leer el documento antes que el profesional, organizar la información, marcar los campos que requieren atención y señalar los requisitos que necesitan verificación. Es lo mismo que hace un practicante bien instruido, y con la misma limitación. El criterio de fondo sigue siendo del juez. Trabajamos con esta filosofía desde que empezamos a construir Marduk (un ecosistema de innovación judicial para la Rama Judicial) y Sherlock-docs (un sistema de procesamiento de documentos legales). Las herramientas amplían la capacidad de ejercer el juicio bien.
Lo que esto significa para el legaltech colombiano
Que Alexander haya publicado TutelaBot en Ollama como modelo descargable gratuito, en lugar de hacerlo detrás de un servicio de suscripción o una API de pago, importa por razones concretas. Un juzgado en Colombia no tiene presupuesto para licencias de software especializado. Una clínica jurídica universitaria tampoco. Un defensor público mucho menos. El modelo de distribución de software libre es el único que puede llegar a esos contextos sin que el costo sea una barrera.
Ese es el ecosistema que Alexander y yo compartimos como visión, con herramientas abiertas, construidas desde adentro del problema y distribuidas sin restricciones de acceso. TutelaBot es la contribución más específica que he visto en ese espacio. No resuelve todo, pero resuelve algo real, con la precisión que viene de entender el problema en su particularidad colombiana. Y eso, en legaltech, es más difícil de lo que parece.
Pruebas con el modelo
Antes de escribir este post corrí TutelaBot con el texto de una tutela real, con los datos personales anonimizados, para verificar que lo que describe la documentación corresponde a lo que devuelve en la práctica. El caso de prueba fue una acción de tutela por violación al artículo 29 de la Constitución (debido proceso, presunción de inocencia, legalidad y defensa), interpuesta contra una Secretaría de Tránsito y Movilidad por irregularidades en la notificación de infracciones de tránsito.
La instalación es un solo comando. ollama pull bladealex/tutelabot descarga las capas del modelo secuencialmente y en cuestión de minutos queda listo. El ollama list confirma lo que ya decía la documentación, con sus 2.0 GB instalados localmente y sin dependencia de ningún servidor externo.
Al iniciar el modelo, lo primero que aparece es su declaración de capacidades en formato JSON. El system prompt declara tres acciones concretas, que son analizar documentos de tutela, extraer información en 57 campos específicos y responder únicamente en JSON. Ese último punto importa, porque el modelo no mezcla texto libre con datos estructurados, lo que hace su salida directamente parseable por cualquier sistema.
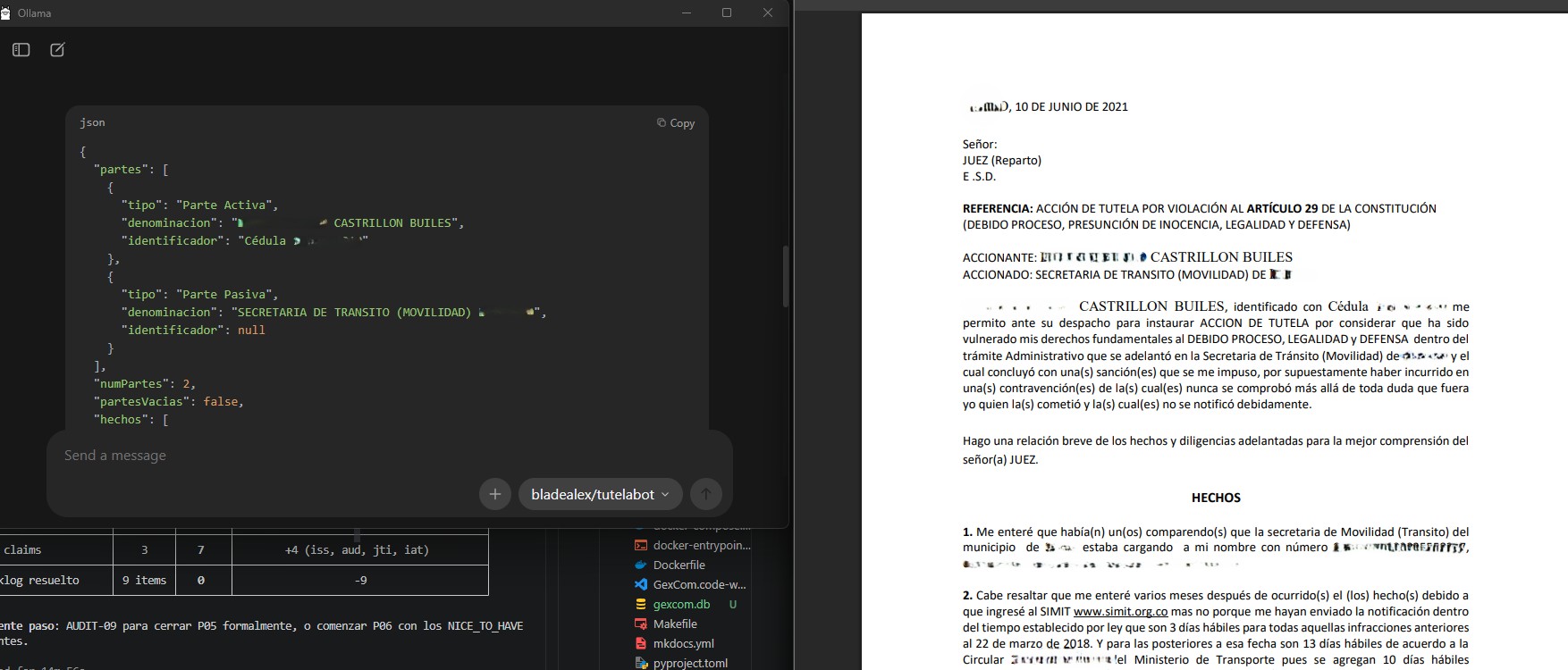
Ingresado el texto de la tutela, el modelo comenzó la extracción de partes procesales. Identificó correctamente a la parte activa y a la parte pasiva sin necesidad de que el documento tuviera un formato estandarizado, leyendo el texto libre y mapeando los campos. Lo que se ve en la captura es exactamente ese momento, el JSON tomando forma en la columna izquierda mientras el documento original permanece visible en la derecha, mostrando la correspondencia entre lo que dice el texto y lo que el modelo extrae.
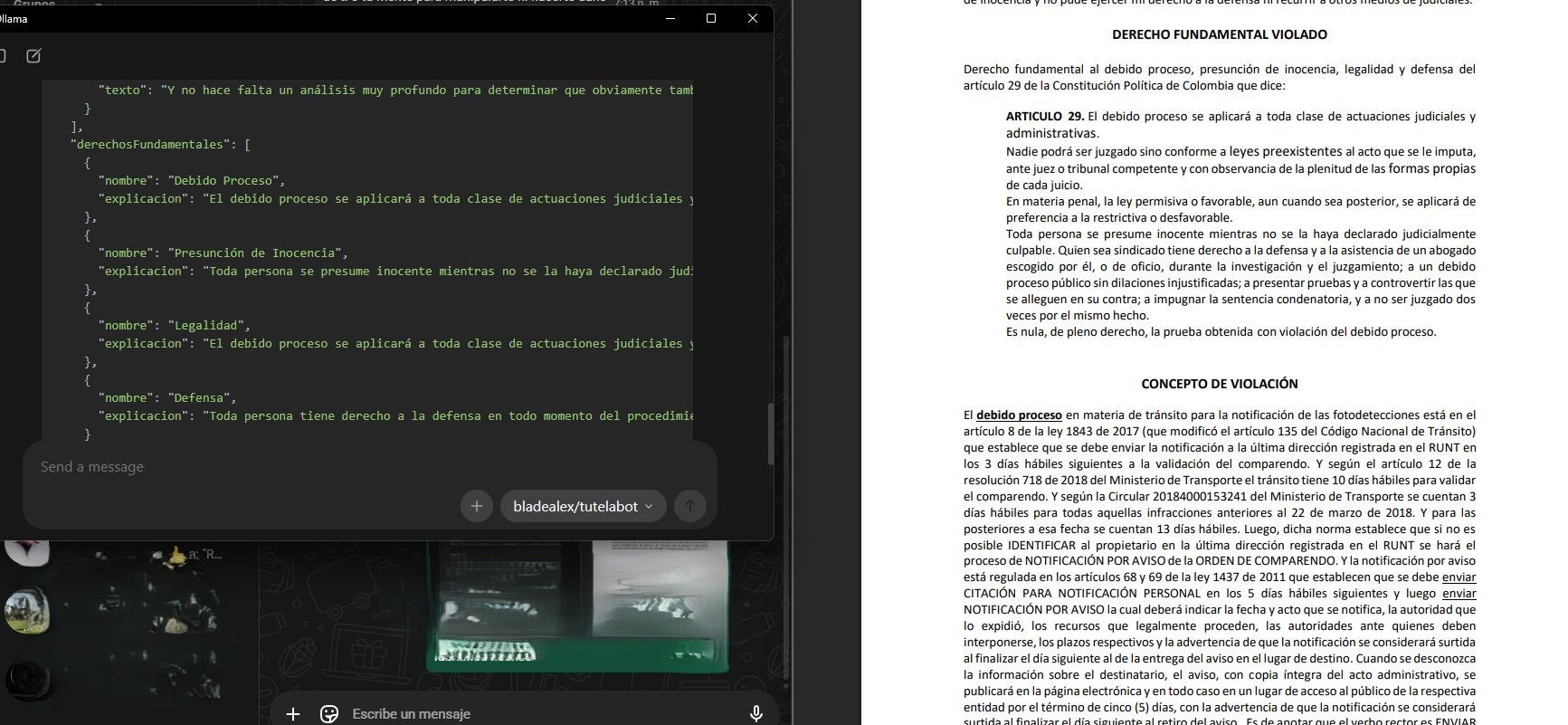
El momento más revelador de la prueba fue la identificación de derechos fundamentales vulnerados. El modelo listó los derechos invocados y los definió en el contexto del ordenamiento jurídico colombiano. Para cada derecho (debido proceso, presunción de inocencia, legalidad, defensa) generó una descripción jurídica precisa, anclada en el artículo 29 de la Constitución. Esa descripción es conocimiento jurídico sobre cómo aplica cada garantía en el contexto procesal colombiano, incorporado desde el entrenamiento del modelo.
Lo que encontré coincide con lo que Alexander documenta. El modelo no alucina, algo importante dado que los modelos generales tienden a generar campos que no existen en el texto. Distingue entre lo que puede extraer directamente del documento y lo que requiere interpretación jurídica. Y la salida es consistentemente JSON, sin texto libre intercalado que rompa el pipeline de automatización.
Por qué esto conecta con Sherlock-docs
Hay algo que me interesa especialmente de que TutelaBot corra localmente con Ollama. Elimina la dependencia de APIs externas y mantiene los documentos fuera de servidores de terceros, un requisito de confidencialidad crítico en el contexto judicial colombiano.
Eso lo hace directamente compatible con la arquitectura que vengo explorando en Sherlock-docs, el proyecto en el que trabajo para el análisis y procesamiento de documentos judiciales. La posibilidad de integrar un modelo especializado como TutelaBot en un pipeline local, donde el documento nunca sale del entorno controlado, abre una ruta que antes requería construir el modelo desde cero. Es una pieza que encaja de forma natural. Sherlock-docs merece su propio espacio, y ese post viene pronto.
Esto es solo el inicio
Lo que Alexander construyó merece más que una reseña técnica. Merece replicarse, extenderse y encontrar comunidad. Un modelo especializado en tutelas hoy puede ser el punto de partida para modelos que analicen acciones populares, nulidades electorales, procesos disciplinarios, o cualquier tipo de actuación judicial que tenga estructura repetida y volumen alto.
Lo que más me entusiasma de TutelaBot es lo que demuestra posible. Alguien con conocimiento real del sistema judicial colombiano y capacidad técnica puede construir una herramienta específica, publicarla en abierto y ponerla a disposición de cualquier juzgado, clínica jurídica o abogado del país sin costo de licencia ni dependencia de un proveedor externo. Ese es el tipo de iniciativa que vale la pena potenciar. Si estás trabajando en algo similar o quieres explorar cómo usar TutelaBot en tu práctica, el modelo está disponible en ollama.com/bladealex/tutelabot y Alexander es la persona indicada para conectar.
Este post es parte de la serie [Construyendo] donde comparto en abierto las herramientas, patrones y decisiones detrás de los proyectos en los que trabajo.